AudioLoader
- class ketos.audio.audio_loader.AudioLoader(selection_gen, channel=0, annotations=None, representation=<class 'ketos.audio.waveform.Waveform'>, representation_params=None, batch_size=1, stop=True, **kwargs)[source]
Class for loading segments of audio data from .wav files.
Several representations of the audio data are possible, including waveform, magnitude spectrogram, power spectrogram, mel spectrogram, and CQT spectrogram.
- Args:
- selection_gen: SelectionGenerator
Selection generator
- channel: int
For stereo recordings, this can be used to select which channel to read from
- annotations: pandas DataFrame
Annotation table
- representation: class or list of classes
Audio data representation. This is a class that must receive the raw audio data and will transform the data into the specified audio representation object.
Classes available in ketos:
- Waveform:
(rate), (resample_method)
- MagSpectrogram, PowerSpectrogram, MelSpectrogram:
audio, window, step, (window_func), (rate), (resample_method)
- CQTSpectrogram:
audio, step, bins_per_oct, (freq_min), (freq_max), (window_func), (rate), (resample_method)
It is also possible to specify multiple audio presentations as a list.
- representation_params: dict or list of dict
Dictionary containing any required and optional arguments for the representation class. If more than one representation is given representation_params must be a list of the same length and in the same order.
- batch_size: int
Load segments in batches rather than one at the time.
- stop: bool
Raise StopIteration when all selections have been loaded. Default is True.
Examples:
Creating an AudioLoader to load selections:
>>> from ketos.audio.audio_loader import AudioLoader, SelectionTableIterator >>> from ketos.data_handling.selection_table import use_multi_indexing >>> import pandas as pd >>> # Load the audio representation you want to pass >>> from ketos.audio.spectrogram import MagSpectrogram >>> # specify the audio representation >>> rep = {'window':0.2, 'step':0.02, 'window_func':'hamming'} >>> # Load selections >>> sel = pd.DataFrame({'filename':["2min.wav", "2min.wav"],'start':[0.10,0.12],'end':[0.46,0.42]}) >>> sel = use_multi_indexing(sel, 'sel_id') >>> # create a generator for iterating over all the selections >>> generator = SelectionTableIterator(data_dir="ketos/tests/assets/", selection_table=sel) >>> # Create a loader by passing the generator and the representation to the AudioLoader >>> loader = AudioLoader(selection_gen=generator, representation=MagSpectrogram, representation_params=rep) >>> # print number of segments >>> print(loader.num()) 2 >>> # load and plot the first selection >>> spec = next(loader) >>> >>> import matplotlib.pyplot as plt >>> fig = spec.plot() >>> fig.savefig("ketos/tests/assets/tmp/spec_loader_2min_0.png") >>> plt.close(fig)
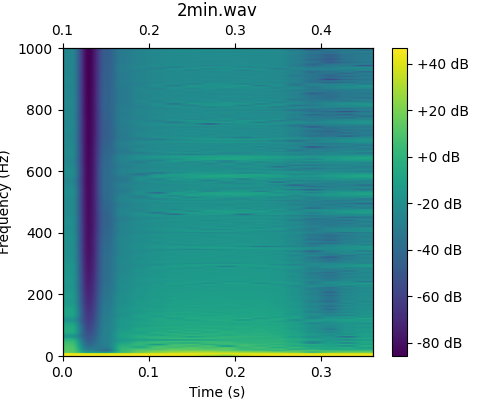
Creating an AudioLoader to load selections made from annotations:
>>> from ketos.audio.audio_loader import AudioLoader, SelectionTableIterator >>> from ketos.data_handling.selection_table import standardize >>> import pandas as pd >>> # Load the audio representation you want to pass >>> from ketos.audio.spectrogram import MagSpectrogram >>> # specify the audio representation >>> rep = {'window':0.2, 'step':0.02, 'window_func':'hamming'} >>> # Load selections >>> annot = pd.DataFrame([{"filename":"2min.wav", "start":2.0, "end":3.0, "label":0}, ... {"filename":"2min.wav", "start":5.0, "end":6.0, "label":0}, ... {"filename":"2min.wav", "start":21.0, "end":22.0, "label":0}, ... {"filename":"2min.wav", "start":25.0, "end":27.0, "label":0}]) >>> annot_std = standardize(table=annot) >>> # create a generator for iterating over all the selections >>> generator = SelectionTableIterator(data_dir="ketos/tests/assets/", selection_table=annot_std) >>> # Create a loader by passing the generator and the representation to the AudioLoader >>> loader = AudioLoader(selection_gen=generator, representation=MagSpectrogram, representation_params=rep) >>> # print number of segments >>> print(loader.num()) 4 >>> # load and plot the first selection >>> spec = next(loader) >>> >>> import matplotlib.pyplot as plt >>> fig = spec.plot() >>> fig.savefig("ketos/tests/assets/tmp/spec_loader_2min_1.png") >>> plt.close(fig)
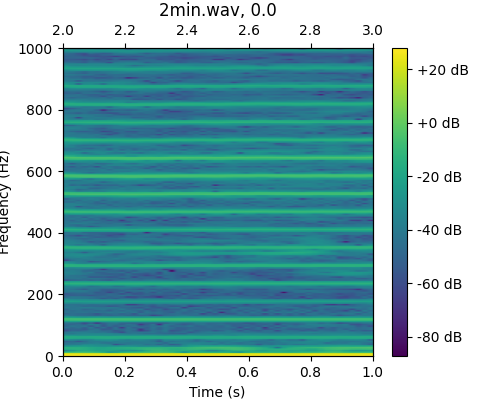
For more examples see child class
audio.audio_loader.AudioFrameLoaderMethods
load(data_dir, filename[, offset, duration, ...])Load audio segment for specified file and time.
num()Returns total number of segments.
reset()Resets the audio loader to the beginning.
skip()Skip to the next audio segment or batch of audio segments without loading the current one.
- load(data_dir, filename, offset=0, duration=None, label=None, **kwargs)[source]
Load audio segment for specified file and time.
- Args:
- data_dir: str
Data directory
- filename: str
Filename or relative path
- offset: float
Start time of the segment in seconds, measured from the beginning of the file.
- duration: float
Duration of segment in seconds.
- label: int
Integer label
- Returns:
- seg: BaseAudio or list(BaseAudio)
Audio segment