AudioFrameLoader
- class ketos.audio.audio_loader.AudioFrameLoader(duration, step=None, path=None, filename=None, channel=0, annotations=None, representation=<class 'ketos.audio.waveform.Waveform'>, representation_params=None, batch_size=1, stop=True, pad=True)[source]
Load audio segments by sliding a fixed-size frame across the recording.
The frame size is specified with the ‘duration’ argument, while the ‘step’ argument may be used to specify the step size. (If ‘step’ is not specified, it is set equal to ‘duration’.)
- Args:
- duration: float
Segment duration in seconds.
- step: float
Separation between consecutive segments in seconds. If None, the step size equals the segment duration.
- path: str
Path to folder containing .wav files. If None is specified, the current directory will be used.
- filename: str or list(str)
relative path to a single .wav file or a list of .wav files. Optional
- channel: int
For stereo recordings, this can be used to select which channel to read from
- annotations: pandas DataFrame
Annotation table
- representation: class or list of classes
Audio data representation. This is a class that must receive the raw audio data and will transform the data into the specified audio representation object. It is also possible to specify multiple audio presentations as a list. These presentations must have the same duration.
- representation_params: dict or list of dict
Dictionary containing any required and optional arguments for the representation class. If more than one representation is given representation_params must be a list of the same length and in the same order.
- batch_size: int
Load segments in batches rather than one at the time.
- stop: bool
Raise StopIteration if the iteration exceeds the number of available selections. Default is False.
- pad: bool
If True (default), the last segment is allowed to extend beyond the endpoint of the audio file.
- Examples:
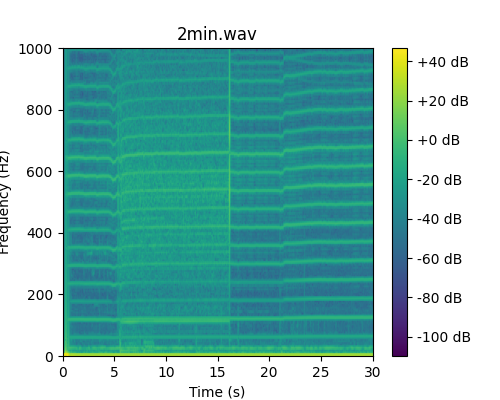
>>> from ketos.audio.audio_loader import AudioFrameLoader >>> # Load the audio representation you want to pass >>> from ketos.audio.spectrogram import MagSpectrogram >>> # specify path to wav file >>> filename = 'ketos/tests/assets/2min.wav' >>> # check the duration of the audio file >>> from ketos.audio.waveform import get_duration >>> print(get_duration(filename)[0]) 120.832 >>> # specify the audio representation parameters >>> rep = {'window':0.2, 'step':0.02, 'window_func':'hamming', 'freq_max':1000.} >>> # create an object for loading 30-s long spectrogram segments, using a step size of 15 s (50% overlap) >>> loader = AudioFrameLoader(duration=30., step=15., filename=filename, representation=MagSpectrogram, representation_params=rep) >>> # print number of segments >>> print(loader.num()) 8 >>> # load and plot the first segment >>> spec = next(loader) >>> >>> import matplotlib.pyplot as plt >>> fig = spec.plot() >>> fig.savefig("ketos/tests/assets/tmp/spec_2min_0.png") >>> plt.close(fig)
Methods
Get the durations of the audio files associated with this instance.
get_file_paths([fullpath])Get the paths to the audio files associated with this instance.